
RAG pipelines are easy to build and hard to evaluate. We have been working on a number of document-heavy applications in the financial services space, and across all of them the same question kept coming up: how do we know the retrieval is actually working? We will use a credit investigation agent as the running example throughout this article. It is a good representative case: dense documents, exact numerical facts, strict auditability requirements, and queries that do not always use the same vocabulary as the source material.
Unit tests will tell you whether the code runs. But they won't tell you whether the right information surfaces when an analyst asks "what is this company's net debt to EBITDA ratio?" against a 150-page 10-K. That is a different question, and it needs a different kind of measurement.
This article walks through how we built the evaluation framework, what pipeline components we were evaluating, and what five controlled experiments taught us about getting retrieval right for financial documents.
The System: What We Are Actually Building
Before the measurements, a quick description of the system. The agent receives a case (a corporate borrower, a loan application, a set of source documents) and produces a structured credit memo. The memo contains facts, figures, and risk assessments, each traceable back to a source document with a citation.
The key design constraint is auditability. Every number in the output must trace back to a retrieved passage. This is not optional in banking: it is a regulatory requirement. A system that produces plausible-sounding numbers with no provenance is not a useful system, it is a liability.
The pipeline has two distinct parts:
- RAG (Retrieval Augmented Generation): handles unstructured sources: PDFs, regulatory text, prior memos. The pipeline retrieves relevant passages and presents them to the LLM as grounded context.
- Tool calls: handle structured sources: API calls to core banking systems, data feeds, databases. These return structured JSON and are cited differently.
This article is about the RAG side only.
The Pipeline Components
The pipeline has two stages: ingestion and retrieval. Ingestion runs once when documents are processed and indexed. Retrieval runs on every query.
Ingestion
Chunking
Before anything gets embedded or indexed, the source documents have to be cut into manageable pieces. How you cut them matters enormously. It shapes everything downstream.
The first decision is what kind of splitter to use. A naive character-count splitter will split wherever it hits the token limit, including mid-sentence, mid-table row, or mid-ratio definition. A chunk that starts in the middle of a sentence produces a degraded embedding: the model has to guess meaning from an incomplete semantic unit. We use LangChain's RecursiveCharacterTextSplitter, which works down a priority list of separators: paragraph break (\n\n) first, then line break (\n), then sentence boundary (. ), then word, then character as a last resort. In practice, nearly all splits happen at paragraph or line boundaries, which means chunks respect natural semantic units in the document.
Token counting uses tiktoken with the cl100k_base encoding (the same tokenizer as the OpenAI embedding models), so the configured chunk size translates directly to actual model token counts.
Parent-child chunking is the second key design choice. The pipeline produces two layers of chunks from each document:
- Parent chunks: large windows of 1024 tokens with no overlap. Each parent is a distinct, non-overlapping section of the document.
- Child chunks: smaller windows of 256 tokens with a 20-token overlap, split from within each parent. Only child chunks are embedded and indexed for retrieval.
Why split this way? The tension in single-size chunking is that small chunks give you precise retrieval (the embedding is focused on one fact) but the LLM gets narrow context (it can only see that one fact). Large chunks give the LLM rich context but produce diffuse embeddings that match too many queries superficially.
The parent-child approach resolves this. Child chunks are small and precise: when a query matches, it is matching a specific, focused claim. But the pipeline does not return the child to the LLM. It does a parent lookup: find the parent that contains the matched child, and return the full 1024-token parent instead. The LLM gets rich context; retrieval stays precise.
The 20-token child overlap handles a practical edge case: when a parent boundary falls in the middle of a sentence, the child that starts that sentence and the child that ends it would each have half the meaning. The small overlap ensures that any sentence crossing a child boundary appears fully in at least one child chunk. All children of the same parent collapse to a single CitedFact in the retrieval output anyway. If multiple children from the same parent are retrieved, the pipeline returns the parent once, using the highest-scoring child's confidence.
Proposition Extraction
Financial statements are dense. A single paragraph might mention revenue, operating income, net income, depreciation, and tax rates: five different facts in 150 words. If you embed that paragraph as a single chunk, the embedding is an average over all five facts. A query about one specific fact has to compete with all the others.
Proposition extraction breaks each parent chunk into atomic factual statements: individual, self-contained claims that can each be embedded precisely. The LLM is asked to decompose the chunk into up to 12 atomic propositions, each a single verifiable fact.
Let's go through a concrete example. Take a parent chunk from Apple's FY2025 10-K:
"The Company's total net sales increased 4% or $15.7 billion during 2025 compared to 2024, driven primarily by higher net sales of iPhone, Services and Mac. Total cost of sales increased $7.5 billion or 4% during 2025 compared to 2024. Gross margin increased $8.2 billion or 6% and gross margin percentage increased to 46.9% compared to 46.2% in 2024. Operating expenses increased $1.7 billion or 4% during 2025 compared to 2024. Net income increased $6.5 billion or 7% during 2025 compared to 2024."
The proposition extractor would decompose this into something like:
- "Total net sales increased 4% during fiscal 2025 compared to fiscal 2024."
- "Total net sales growth in fiscal 2025 was $15.7 billion."
- "Net sales growth was driven primarily by iPhone, Services, and Mac."
- "Total cost of sales increased $7.5 billion, or 4%, in fiscal 2025."
- "Gross margin increased $8.2 billion, or 6%, in fiscal 2025."
- "Gross margin percentage was 46.9% in fiscal 2025, up from 46.2% in fiscal 2024."
- "Operating expenses increased $1.7 billion, or 4%, in fiscal 2025."
- "Net income increased $6.5 billion, or 7%, in fiscal 2025."
Eight clean retrieval targets, each precisely matchable. A query about gross margin goes straight to propositions 5 and 6 without competing with the net income or cost of sales context.
Each proposition is then prefixed with the source identifier before embedding. What actually gets embedded is: [financial_statement/apple_fy2025_10k] Gross margin percentage was 46.9% in fiscal 2025, up from 46.2% in fiscal 2024. The prefix grounds the embedding to its document, preventing cross-document false matches.
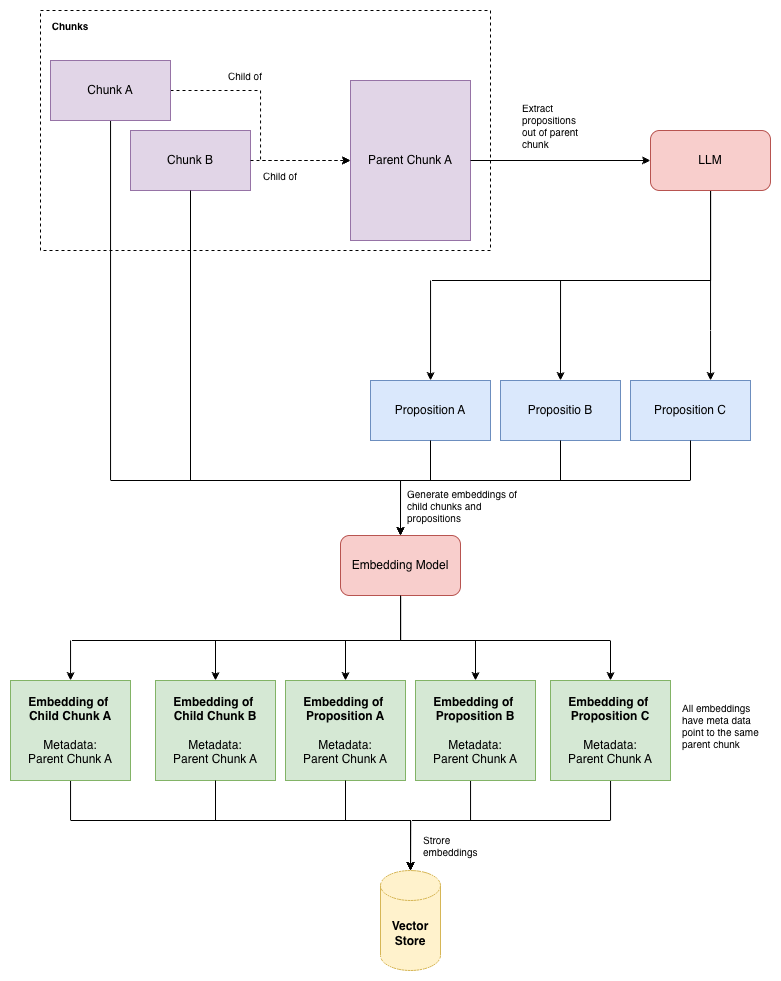
Proposition extraction: each parent chunk is decomposed into atomic factual statements, each embedded separately for precise retrieval.
To summarise what gets embedded and what does not:
| Chunk type | Embedded? | Indexed for retrieval? | Returned to LLM? |
|---|---|---|---|
| Parent chunk (1024 tokens) | No | No | Yes: full context |
| Child chunk (256 tokens) | Yes (without proposition mode) | Yes | No |
| Proposition (1 atomic fact) | Yes (with proposition mode) | Yes | No |
The proposition identifies where in the document the answer lives; the parent gives the LLM the surrounding context it needs to reason correctly. Nothing bigger than a proposition is ever embedded. Nothing smaller than a parent is ever sent to the LLM.
Context Enhancement
This is the Anthropic contextual retrieval technique. Before embedding each chunk, an LLM call generates a short sentence describing where the chunk sits in the document: which section it belongs to, what topic it covers, what precedes it.
The problem it solves is straightforward. A chunk that reads "The ratio was 3.2x" is meaningless out of context. You cannot embed it in a way that matches "what is the net debt to EBITDA ratio?" because the embedding has no idea it is talking about debt ratios. With a context prefix ("This passage from the FY2025 financials describes the company's leverage ratio") the embedding becomes meaningful.
The stored chunk content remains the original text (for citation and display). Only the vector carries the context. So the analyst sees the original source text, but retrieval works correctly.
One important note: context enhancement was intentionally left out of all five experiments in this article, and the reason is cost. The technique requires an LLM call for every child chunk at ingestion time, and each call sends the entire source document as context so the model can situate the chunk within it. For a 150-page 10-K with hundreds of child chunks, that is hundreds of full-document LLM calls. OpenAI's prompt caching makes this cheaper than it sounds, since the document prefix is shared across all calls for the same document and the cached tokens are billed at a fraction of the normal rate. But even with caching, the cost and latency are significant enough that we held it back while we established a strong baseline with the cheaper components. Given that the experiment 6 configuration already passes both thresholds comfortably, the remaining headroom from context enhancement is a future experiment rather than an immediate priority.
Retrieval
Hybrid Retrieval
Pure semantic search (embedding similarity) works well when the query and the document use the same vocabulary. Financial documents are a mixed bag: they contain natural-language prose, but also exact terminology that matters: "net debt to EBITDA", "Article 395", "PSC disclosure". A semantic retriever might find a passage about leverage ratios even if the exact term does not appear. But a passage that uses the exact phrase "net debt / EBITDA" should rank highly regardless of semantic proximity.
This is why we use hybrid retrieval: a combination of dense (semantic) and lexical (keyword) retrieval, fused together.
The flow works like this:
- The original query is sent to an LLM to generate three alternative phrasings (different vocabulary, different angle, same intent). So "what is the net debt to EBITDA ratio?" might expand to include "leverage ratio from the audited accounts" and "long-term debt relative to earnings".
- All four queries (original + three expansions) are run through both a dense retriever (OpenAI embeddings, cosine similarity against the vector store) and a BM25 retriever (keyword frequency index, exact term matching).
- All the resulting ranked lists (up to eight of them) are merged using Reciprocal Rank Fusion (RRF). A chunk that ranks reasonably well in many lists beats a chunk that tops only one list.
The result is a candidate pool of the top 100 chunks, ordered by their fused score.
Reranking
The 100-chunk candidate pool is then passed through a reranker. The reranker's job is to cut this down to the final top-k that actually gets presented to the LLM.
Why a separate reranking step? The RRF score is a fusion proxy: it rewards chunks that appear consistently across multiple retrieval lists. It is a good signal, but it is not a direct relevance judgment. The reranker makes a direct judgment: given this specific query and this specific passage, how relevant is this passage?
The key difference is that the reranker sees both the query and the passage at the same time (a cross-encoder), rather than encoding them independently and comparing their vectors. This is more expensive but more accurate: the model can reason about whether the passage actually answers the question, not just whether their embeddings are nearby.
We used two rerankers in our experiments:
- CrossEncoderReranker: runs
BAAI/bge-reranker-baselocally. No API needed, but requires torch and a bit of memory. - CohereReranker: calls Cohere's
rerank-v3.5API over HTTP. Multilingual, no local model, the one we used in the final experiments.
How We Measure Quality
Three Layers of Evaluation
The evaluation framework is deliberately split into three layers, and you build them in order:
| Layer | What it measures |
|---|---|
| 1: Retrieval | Are the right chunks surfaced for each query? |
| 2: Generation faithfulness | Is the synthesized report grounded in what was retrieved? |
| 3: End-to-end | Does a full case produce a correct, compliant report? |
You build Layer 1 first because retrieval quality is upstream of everything else. A faithfulness score of 0.9 on a bad retrieval stack is meaningless: the model is faithfully reproducing the wrong information.
The experiments in this article are all Layer 1 and Layer 2.
Custom Metrics: Always On, No LLM Required
Citation coverage is a structural check: every cited fact the pipeline produces must carry at least one citation object. Score = facts with citation / total facts. A score below 1.0 means the system is returning facts with no provenance. That is a hard failure for the audit trail. We gate on 1.00.
This metric is deterministic. It does not require a judge LLM. And it remained 1.0 across all five experiments, which is expected: provenance is enforced by the pipeline architecture, not by the LLM.
RAGAS Retrieval Metrics: Precision and Recall
For retrieval quality, we use two RAGAS LLM-as-judge metrics: context precision and context recall. Both require a judge LLM (we used GPT-4o) and both require annotated reference facts.
The reference facts live in a file that you fill in (or let Claude or ChatGPT fill in). For each query, we wrote out the ground-truth facts that the retrieval pipeline should find. For example, for the query "What is the company's net debt to EBITDA ratio and interest coverage ratio?", the expected facts include things like: "Total term debt principal was $91,281 million as of September 27, 2025" and "Implied EBITDA of approximately $144,748 million based on operating income plus depreciation."
These are not vague: they are specific, verifiable facts sourced from the actual document. Writing them well is important. A poorly written reference makes the metric meaningless.
Context Precision asks: of the chunks we retrieved, what fraction were actually relevant? But it is not a simple precision: it is an average precision (AP), which weights rank position. Retrieving the right chunk at position 1 is better than retrieving it at position 4. The LLM judge evaluates each retrieved chunk for relevance against the reference facts, and the AP formula penalises a pipeline that buries relevant chunks below irrelevant ones.
Context Recall asks: do the retrieved chunks collectively cover all the facts in the reference? The LLM judge decomposes the reference into individual statements, then checks whether each statement can be attributed to at least one retrieved chunk. Score = covered statements / total statements.
Our thresholds: precision ≥ 0.80, recall ≥ 0.75. Recall here is quite important. In a banking context, it is worse to miss a fact (low recall) than to retrieve one extra irrelevant chunk (low precision). We set the bar higher for precision to keep the context clean.
RAGAS Faithfulness: Why the 0.5 Threshold Exists
Layer 2 measures whether the synthesized report is grounded in what was retrieved. RAGAS Faithfulness works like this: the judge LLM decomposes the report into atomic claims and for each one asks: can this be inferred from the retrieved contexts? Score = supported claims / total claims.
A score of 1.0 would mean every claim in the report has explicit support in a retrieved passage. That sounds like the right target, but it is not achievable for credit memos, and it is not because the model is hallucinating.
Credit memos require interpretive prose. A senior analyst does not just relay facts: they synthesise them: "The company's leverage has improved year-over-year, supported by EBITDA growth outpacing debt reduction." That sentence is valid, it is grounded, but it is an inference over multiple facts. RAGAS cannot verify it because no single retrieved passage says exactly that. The judge marks it as unsupported, which drives the score down regardless of whether it is true.
This is a fundamental limitation of faithfulness metrics for analytical documents. They are calibrated for factoid Q&A where every claim maps directly to a retrieved sentence. Credit memos, legal analysis, financial commentary, and similar genres require synthesis. The model is supposed to connect dots across multiple sources.
The realistic ceiling for a well-grounded credit memo is around 0.50. Roughly half the claims are directly verifiable verbatim; the other half are valid inferences. We set the threshold at 0.50 accordingly. Our pipeline achieved 0.89 in the final experiment, which is unusually high. It means the synthesis node stays close to retrieved facts and avoids editorialising. That is a deliberate design choice in the synthesis prompts, not a coincidence.
Numeric Citation Rate: The Harder Grounding Check
Faithfulness covers all claims, including interpretive prose. But there is a stricter test for numbers specifically: numeric_citation_rate.
The metric is simple: scan every number that appears in the generated report (percentages, monetary figures, ratios, counts) and check whether it traces back to a cited source with a confidence score above a minimum threshold. Score = numbers with a citation / total numbers in the report.
A number that appears in the report without a traceable source is a hard failure regardless of whether it happens to be correct. An LLM can produce a plausible-looking figure that is slightly off, rounded differently, or drawn from a different period than intended. The only way to catch this is to require that every number point back to a specific retrieved passage. We gate on 0.95, accepting a small tolerance for edge cases like derived calculations, while treating the threshold as effectively mandatory for raw figures lifted directly from source documents.
This is the metric that matters most for a banking use case. Faithfulness tells you whether the language is grounded. Numeric citation rate tells you whether the numbers are.
The Five Experiments
All five experiments use the same corpus (Apple's FY2025 Form 10-K), the same 15-query test suite targeting financial statement data, the same OpenAI embedder, and the same hybrid retrieval architecture. We change one variable at a time.
| Experiment | Chunk size | Structure-aware splitter | Proposition generator | Reranker | Precision | Recall | Passed |
|---|---|---|---|---|---|---|---|
| 2 | 128 | No | No | BAAI/bge-reranker-base | 0.710 | 0.738 | No |
| 3 | 256 | No | No | BAAI/bge-reranker-base | 0.869 | 0.743 | No |
| 4 | 256 | Yes | No | BAAI/bge-reranker-base | 0.907 | 0.757 | Yes |
| 5 | 256 | Yes | Yes | BAAI/bge-reranker-base | 0.840 | 0.717 | No |
| 6 | 256 | Yes | Yes | Cohere | 0.812 | 0.862 | Yes |
Thresholds: precision ≥ 0.80, recall ≥ 0.75.
Experiment 2 → 3: Chunk Size
Doubling chunk tokens from 128 to 256 improved precision dramatically (0.710 → 0.869) but recall remained just below threshold (0.743). Why?
At 128 tokens, the chunker frequently splits mid-sentence, mid-table row, or mid-ratio definition. A chunk that starts halfway through a sentence is semantically incomplete. Its embedding reflects partial meaning. Doubling the size keeps more semantic units intact: a full sentence about revenue, a complete table row with all columns.
The precision improvement is large because fewer nonsense partial-sentence chunks rank highly. The recall improvement is smaller because we still need the right parent window to contain the fact. Chunk size helps, but boundary placement matters too.
Experiment 3 → 4: Structure-Aware Splitting
This is the most significant single change. Adding a structure-aware splitter (one that respects section boundaries, headings, and natural document structure) pushed precision to 0.907 and recall to 0.757, and the suite passed for the first time.
The generic recursive splitter used in experiments 2 and 3 splits on paragraph and sentence boundaries, but it has no concept of document structure. It will happily split a chunk right after the "Capital Return Program" heading and before the numbers that follow it. The heading ends up in one chunk; the relevant data ends up in the next.
The structure-aware splitter keeps a section's heading with the content that follows it. For a 10-K with clear section structure, this is the difference between retrieving a chunk that says "Capital Return Program - In addition to its contractual cash requirements" and one that contains the actual buyback figures.
For documents with rich structure (SEC filings, regulatory text, policy manuals, legal contracts) structure-aware splitting is not an optional enhancement. It is the correct unit of analysis.
Experiment 4 → 5: Proposition Generator
Adding the proposition generator made things worse. Recall dropped from 0.757 to 0.717, falling back below threshold. This was the counterintuitive result.
The hypothesis is about the nature of the queries. Several of the 15 queries are multi-fact: "What is the net debt to EBITDA ratio and interest coverage ratio?" To answer this well, the retrieved context needs to cover both facts. A parent chunk containing both, spread across a few sentences, covers both in one retrieval hit.
Propositions optimise for single-fact precision. Each proposition is one claim, embedded precisely. But a query asking for two things needs two different propositions to surface, both in the same top-k result set. The competition is tougher. The proposition pool is larger. And some multi-fact context that lived naturally in a single paragraph gets split across multiple propositions, neither of which individually satisfies the full recall requirement.
Propositions help in entity-dense knowledge bases where facts are spread across many documents and you need to find one specific claim. For compound financial questions against a single document, they can fragment context that was better left together.
Experiment 5 → 6: Cohere Reranker
Adding the Cohere reranker on top of the proposition configuration fixed the recall problem entirely, and then some. Recall jumped from 0.717 to 0.862, the best across all experiments. The suite passed again. Precision stayed above threshold at 0.812.
Why does this combination work? Propositions create a fine-grained candidate pool of atomic facts. The 100-candidate pool after hybrid retrieval now contains many more individually precise claims than it did with parent chunks. But the RRF-merged ranking does not know which of those propositions together answer the query. The reranker does: it scores each (query, proposition) pair directly and selects the subset that best addresses the question in aggregate.
Propositions alone give you a precise candidate pool. The reranker selects the right subset from it. They are designed to work together. Do not evaluate either in isolation.
Layer 2: Does Better Retrieval Actually Improve the Output?
Improving retrieval is not valuable unless it leads to better final reports. After settling on the experiment 6 configuration, we ran the synthesis faithfulness suite, passing a full credit case through the pipeline and evaluating the generated report.
The results:
| Metric | Score | Threshold | Result |
|---|---|---|---|
citation_coverage |
1.000 | 1.00 | Pass |
numeric_citation_rate |
0.984 | 0.95 | Pass |
faithfulness (RAGAS) |
0.889 | 0.50 | Pass |
98.4% of numbers in the report trace to a cited source document. 1.6% do not (within our tolerance of 5%). The RAGAS faithfulness of 0.889 is notably above the 0.50 realistic ceiling we discussed earlier, which tells us the synthesis prompts are doing their job: the model is staying close to retrieved evidence rather than editorialising.
The chain holds. Better retrieval produces better-grounded reports.
What Comes Next
A few things are still open:
Context enhancement was not included in any of the five experiments. It is the most promising remaining lever, especially for documents where sections lack clear headings and the chunk content is ambiguous without surrounding context. Anthropic's original paper reported large gains; we have not measured ours yet.
The proposition recall problem needs more investigation with a larger query set. The 15-query suite is enough to see a trend but not enough to be confident about the mechanism. It is possible that with a different query mix (more single-fact, fewer compound) propositions help rather than hurt.