
بناء RAG أمر سهل. فمع بضعة أسطر برمجية من LangChain أو LlamaIndex تُنجز نموذجًا أوليًا يجيب على الأسئلة ويبدو مقنعًا بما يكفي لتقديم عرض توضيحي. غير أنّ الانتقال من هذا النموذج الأولي إلى نظام موثوق في بيئة الإنتاج هو ما يستغرق وقتًا فعليًا.
لا يعني ذلك ضرورةً تعقيد البنية. كثيرًا ما ينبع الحل من التحسين الدقيق: حجم القطع المناسب، وتمثيل صحيح للبنية، وإعادة ترتيب Reranking ذكي. لكن ما لا يمكن إصلاحه دون قياسه هو معرفة ما إذا كانت هذه التحسينات تُحدث فارقًا فعليًا.
في هذا المقال نستعرض كيف بنينا وقيّمنا نظام RAG لـ وكيل التحقيق الائتماني في أحد البنوك، بما في ذلك المقاييس التي اخترناها، وكيف صمّمنا التجارب، وما الذي نجح فعليًا وما لم ينجح.
النظام
المستخدم النهائي هو محلل ائتماني يعمل في مجال تمويل الشركات. يُقيّم طلبات القروض، ويُنجز هذا العمل من خلال استعراض أوراق مالية متعددة ووثائق عامة وبيانات داخلية للبنك. الناتج النهائي هو مذكرة ائتمانية تُقدَّم إلى لجنة الائتمان.
بُني الوكيل حول هذا السير الوظيفي. يُقدَّم له مجموعة وثائق وإطار مذكرة ائتمانية، ويُولّد المحتوى لكل قسم، ويستشهد بالمصادر لدعم كل ادعاء.
الاستشهادات ليست جانبًا مريحًا إضافيًا؛ بل هي ضرورة مهنية. محلل الائتمان مسؤول أمام لجنته عن كل رقم وتأكيد يدرجه في المذكرة. لو أخطأ الوكيل واستشهد بمصادر خاطئة أو أضاف أرقامًا غير موجودة في الوثائق، يُشكّل ذلك مشكلة إجرائية وليس مجرد خطأ برمجي.
تتمثل إحدى التوترات الرئيسية في RAG مقابل استدعاء الأداة: كثيرًا ما تكون الأدوات المُصنَّفة المدعومة بقاعدة بيانات منظَّمة (SQL أو Pandas) أفضل للأرقام. لكنها تفترض وجود هيكل بيانات نظيف ومنظَّم. يُقدَّم الوكيل بيانات مالية من الواقع: ملفات PDF لتقارير سنوية، وملاحظات اجتماعات الائتمان، وبيانات Excel، وتقارير خارجية. RAG أكثر نعومةً في التعامل مع تنوع التنسيقات وعدم الانتظام في الهيكل.
مكونات خط الأنابيب
الاستيعاب
للتبسيط، نستخدم ملف PDF واحدًا: تقرير Apple السنوي 10-K لعام 2025. يحتوي على جداول مالية، وشرح نصي، وملاحق، وتقارير المخاطر. وهو نموذج جيد للتعقيدات الهيكلية التي نتوقع مواجهتها في بيانات البنك.
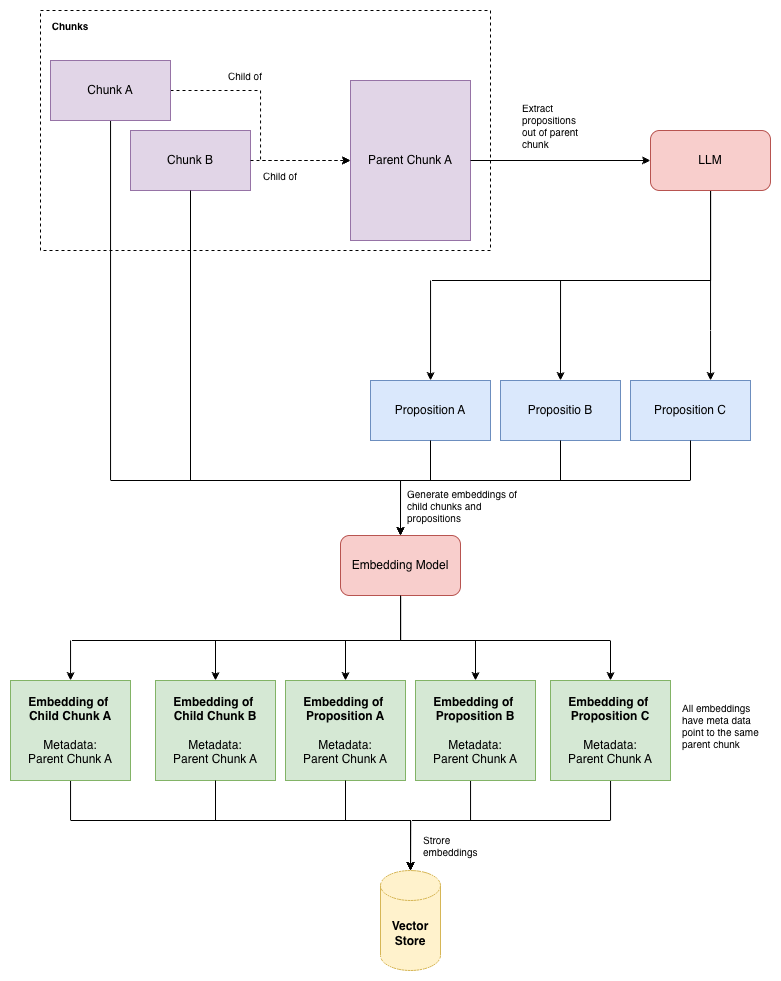
التقسيم Chunking
نستخدم RecursiveCharacterTextSplitter مع tiktoken cl100k_base لعدّ الرموز بدلاً من الأحرف، مع منهجية قطع الأم والطفل (parent-child chunking). نُخزّن قطعًا أبًا بحجم 1024 رمز وقطعًا طفلاً بحجم 256 رمز مع تداخل 20 رمزًا. تُفهرَس قطع الطفل وتُسترجع، أما قطع الأب فتُمرَّر إلى LLM كسياق. يُعطي هذا دقةً أكبر في الاسترجاع مع حفاظ على السياق الكافي للتوليد.
استخلاص الاقتراحات Proposition Extraction
الاقتراح هو بيان واقعي ذري ومستقل: "أبلغت Apple عن إيرادات بلغت 124.3 مليار دولار في الربع الأول من السنة المالية 2025" هو اقتراح واحد. "أبلغت Apple عن نمو" ليس كذلك.
نبدأ باستخراج الاقتراحات من كل قطعة أب بواسطة LLM. والفكرة هي أن قطعة نصية طويلة قد تحتوي على خمسة عشر بيانًا واقعيًا؛ قطعة الاقتراح بأسلوب الاسترجاع تُشير مباشرةً إلى البيان الواقعي المطلوب لا إلى الفقرة التي تحتوي على البيان في مكان ما.
مثال: بعد معالجة قسم "الربع الأول من السنة المالية 2025" في تقرير 10-K لـ Apple، قد نحصل على ما يلي من اقتراحات:
- سجّلت Apple في الربع الأول من السنة المالية 2025 إيرادات بلغت 124.3 مليار دولار.
- بلغ صافي دخل Apple في الربع الأول من السنة المالية 2025 نحو 36.3 مليار دولار.
- نمت إيرادات الخدمات في الربع الأول من السنة المالية 2025 بنسبة 14% على أساس سنوي.
- أعلنت Apple عن حصة سوقية متزايدة لـ iPhone في الأسواق الناشئة في الربع الأول من السنة المالية 2025.
- واصل قطاع Mac نموه في الربع الأول من السنة المالية 2025 مدفوعًا بالطلب على MacBook Pro.
- أوجد عدم اليقين الجيوسياسي ضغطًا محتملاً على الإيرادات الدولية في الربع الأول من السنة المالية 2025.
- شهدت إيرادات قطاع Wearables بعض الضغط في الربع الأول من السنة المالية 2025.
- ارتفع هامش الربح الإجمالي لـ Apple في الربع الأول من السنة المالية 2025 مقارنةً بالفترة ذاتها من العام السابق.
نُضيف بادئة للتضمين (prefix embedding) تُحدّد السياق: "استناداً إلى التقرير السنوي Apple FY2025 10-K:"
يُبيّن الجدول التالي ما يُخزَّن فعلياً في قاعدة البيانات المتجهية:
| نوع القطعة | المحتوى | يُفهرَس؟ | يُمرَّر للـ LLM؟ |
|---|---|---|---|
| قطعة الأب | فقرات نصية أصلية (1024 رمز) | لا | نعم (كسياق) |
| قطعة الطفل | شرائح أصغر (256 رمز) | نعم | لا |
| اقتراح | بيان واقعي ذري | نعم | لا |
الاسترجاع الهجين Hybrid Retrieval
نجمع الاسترجاع الكثيف Dense (التضمينات المتجهية) مع BM25 ثم ندمج النتائج باستخدام RRF (Reciprocal Rank Fusion). نُوسّع الاستعلام إلى أربعة استعلامات بصياغات مختلفة لزيادة التغطية، ونجمع 100 قطعة مرشّحة قبل إعادة الترتيب Reranking.
إعادة الترتيب Reranking
نُقلّص النتائج من 100 قطعة مرشّحة إلى أفضل 20 باستخدام Cross-Encoder Reranker. جرّبنا نموذجَين:
- CrossEncoderReranker: باستخدام نموذج
BAAI/bge-reranker-base، يعمل محليًا دون رسوم API. - CohereReranker: باستخدام نموذج
rerank-v3.5، يتطلب مفتاح API لكنه يُقدّم في العادة دقةً أعلى.
كيف نقيس الجودة
ثلاث طبقات للتقييم
| الطبقة | ما يقيسه | الأداة/الأسلوب |
|---|---|---|
| الطبقة 1: الاسترجاع | هل نسترجع المعلومات الصحيحة؟ | RAGAS Precision & Recall |
| الطبقة 2: التوليد | هل يستشهد النظام بالمصادر بشكل صحيح؟ | citation_coverage & numeric_citation_rate & faithfulness |
| الطبقة 3: المحتوى | هل المخرجات جاهزة للعمل؟ | مراجعة يدوية |
مقاييس مخصصة
citation_coverage: لكل ادعاء في المذكرة الائتمانية، هل يُقدَّم اقتباس مرجعي؟ نحسبها بالصيغة: عدد الادعاءات المستشهَد بها ÷ إجمالي الادعاءات. هدفنا 1.0 (استشهاد كامل). لا مجال للتساهل في تقارير الائتمان.
RAGAS Precision & Recall
Context Precision: ما نسبة السياق المسترجَع التي تتعلق فعلاً بالسؤال؟ تعكس هذه المقياس نسبة الضوضاء وتُقيّم دقة خطوة الاسترجاع. حدّنا الأدنى ≥ 0.80.
Context Recall: ما مدى تغطية السياق المسترجَع للإجابة المرجعية؟ تعكس هذه المقياس القدرة على استرجاع المعلومات الضرورية. حدّنا الأدنى ≥ 0.75.
RAGAS Faithfulness
هل تستند جميع ادعاءات الإجابة المُولَّدة إلى السياق المُقدَّم؟ تكشف عن الهلوسة بمعنى الادعاءات التي لا يدعمها السياق. حدّنا الأدنى 0.5 وهو حدّ متحفّظ، إذ إنّ السقف الواقعي لـ Faithfulness منخفض حتى للأنظمة الجيدة. حققنا 0.89 وهو نتيجة ممتازة.
معدل الاستشهاد الرقمي Numeric Citation Rate
لكل ادعاء رقمي في المذكرة الائتمانية: هل يُرفَق به اقتباس رقمي؟ حدّنا الأدنى ≥ 0.95. هذا هو الخطّ الأحمر للاستخدام القانوني والامتثالي.
التجارب الخمس
| التجربة | حجم القطعة | مراعٍ للبنية؟ | اقتراح؟ | Reranker | Precision | Recall | نجحت؟ |
|---|---|---|---|---|---|---|---|
| 2 | 128 | لا | لا | CrossEncoder | 0.710 | 0.680 | ❌ |
| 3 | 256 | لا | لا | CrossEncoder | 0.869 | 0.724 | ❌ |
| 4 | 256 | نعم | لا | CrossEncoder | 0.907 | 0.757 | ✅ |
| 5 | 256 | نعم | نعم | CrossEncoder | 0.891 | 0.717 | ❌ |
| 6 | 256 | نعم | لا | Cohere | 0.921 | 0.862 | ✅ |
التجربة 2 ← 3: حجم القطعة
رفع حجم القطعة من 128 إلى 256 رمزًا أدى إلى قفزة في Precision من 0.710 إلى 0.869. القطع الأصغر جدًا تُجزّئ الجمل وتتسبب في ضجيج غير ضروري. يُعطي حجم 256 قدرًا أفضل من السياق المتماسك مع الحفاظ على استهداف جيد.
التجربة 3 ← 4: التقسيم المراعي للبنية
نجحت التجربة الرابعة في المرة الأولى بـ Precision 0.907 و Recall 0.757. التقسيم المراعي للبنية يحترم حدود الفقرات والجداول، بدلاً من التقسيم في منتصف جملة أو عمود جدول.
التجربة 4 ← 5: مولّد الاقتراحات
جعلت الأمور أسوأ. انخفض Recall من 0.757 إلى 0.717. يستلزم توليد الاقتراحات تحويل النص الأصلي إلى صياغة مُعاد صياغتها. حين يتعذر الاسترجاع مطابقة المصطلحات الدقيقة من الوثيقة الأصلية إلى الاقتراحات المُعاد صياغتها، يتدهور Recall. من المرجح أن يكون ذلك مرتبطًا بالبيانات المالية الرقمية التي لا تتحمّل أي إعادة صياغة.
التجربة 5 ← 6: Cohere Reranker
عودة إلى تكوين التجربة 4 (دون اقتراحات) مع استبدال CrossEncoder بـ Cohere Reranker. النتيجة: Recall 0.717 ← 0.862 وهو أفضل نتيجة في الجدول. تفوّق Cohere Reranker واضح في فهم الأسئلة المالية ذات الطابع المؤسسي.
الطبقة 2: التوليد
على التجربة الأفضل (التجربة 6) قيّمنا جودة التوليد:
- citation_coverage: 1.000 - جميع الادعاءات مُستشهَد بها (هدفنا ≥ 1.0)
- numeric_citation_rate: 0.984 - تقريبًا كل رقم مُستشهَد به (هدفنا ≥ 0.95)
- faithfulness (RAGAS): 0.889 - ممتاز (هدفنا ≥ 0.5)
النتائج واعدة جدًا لسياق الامتثال المصرفي.
ما التالي
أولوية قصوى في الخطوة التالية: تحسين السياق Context Enhancement باستخدام تقنية Anthropic لتعزيز كل قطعة بسياق وثيقي إضافي قبل التضمين. أغفلناه في هذه التجارب بسبب التكلفة لكنه مرشّح قوي لرفع Recall.
كذلك يستحق تأثير الاقتراحات المزيد من البحث. سببُ إضرار الاقتراحات بـ Recall يحتمل مساعدتها في أسئلة معقولة أخرى.